[데이터 애널리스트 공부] 데이터를 잘 활용하는 일본기업_메루카리_더 나은 의사결정을 지원하기 위한 효과 검증 지침서!
https://note.com/mercari_data/n/n2564f839cfd7
より良い意思決定の支援をするための"効果検証 虎の巻"|Mercari Analytics Blog
今回は、メルカリのAnalyticsチームの中でも主にビジネス分析やマーケティング分析を行うGrowth Analytics Teamからの記事です。 Analyticsチームは、以下のミッションを通じて事業に貢献するチーム
note.com
이번에는, 메루카리의 Analytics 팀 중에서도 주로 비즈니스 분석이나 마케팅 분석을 실시하는 Growth Analytics Team으로부터의 기사입니다. Analytics 팀은 아래 미션을 통해 사업에 기여하는 팀입니다.
1. Provide actionable insights and help people make better decisions(실행 가능한 인사이트를 제공하고 더 나은 의사결정을 지원한다)
2. Democratize data and empower everyone with analytics(데이터의 민주화를 추진하고 모두의 분석력을 높여간다)
그런 Analytics 팀에서 "효과 검증 지침서"라는 것을 도입했습니다.
주된 목적은 이하의 2개 입니다.
1. Analytics 팀 내 암묵적으로 집약한 것을 언어화 및 침투시킴으로써 멤버의 아웃풋 품질 향상
2.누가 해도 같은 아웃풋이 되는 것에 시간을 들이기보다는 과제의 깊이나 시책 입안 등에 노력을 기울여 총화(総和)로서의 사업 공헌량의 최대화
여담이지만, 누가 해도 같은 아웃풋이 되는 영역(표준적인 A/B 테스트 등)이라고 하는 것은, 장래적으로 자동화되거나 AI로 대체되어 갈 것이기 때문에, 데이터 애널리스트로서의 캐리어를 생각하는데 있어서도, 보다 창조성을 수반하는 분석 영역에 포커스 하는 것이 좋지 않을까 생각하고 있습니다.이번 주제는 아니지만, 메루카리는 프로덕트의 A/B 테스트 자동화도 진행되고 있으며, 애널리스트는 보다 테스트 결과의 사후 분석 등에 시간을 할애할 수 있게 되어 있습니다.
https://engineering.mercari.com/blog/entry/20221212-dc31d8e3d8/
メルカリにおけるA/Bテスト分析自動化の取り組み | メルカリエンジニアリング
こんにちは、メルカリのレコメンデーションチームで Software Engineer をしている @yaginuuun です。主に推薦を通じたホーム画面における体験改善に取り組んでいます。元々はデータアナリストと
engineering.mercari.com
전제조건으로, 메루카리의 사업판단이나 프로덕트의 사양변경에 있어서는 공식적인 의사결정기준으로서 유의수준의 규정이 있거나 실험데이터가 아닌 관찰데이터에 근거한 인과추론을 바탕으로 한 결과는 권장되지 않는 등 비교적 민감한 분석결과가 요구되는 경우가 있습니다.한편, 현장에서 실시하는 개별 캠페인 시책에서는 원활한 의사결정을 할 수 있도록 여러가지 분석 어프로치를 구사해 효과 검증을 실시하고 있습니다.
여기서 "효과 검증 지침서"의 초판은, A/B 테스트(랜덤화 비교 실험)가 어려운 효과 검증에 포커스를 해 작성했습니다.분석 현장에서는 A/B 테스트와 같이 동질의 비교군을 준비할 수 없는 어려운 분석 과제에 직면할 수 있습니다.그런 경우에 대해서 지침서에 기재되어 있는 접근법을 일부 소개하겠습니다.
목차
1.케이스별 접근방법
2.어떻게 대처하여 의사결정에 공헌하고 있는가
2-1.DID/CausalImpact
2-2.교락 조정 (경향 스코어 매칭/IPW)
2-3.트렌드 비교
3.정리
1. 케이스별 접근방법
효과 검증 방법의 선정은 대략적으로 아래와 같은 플로우 차트에 따라 실시할 수 있다고 생각했습니다.

효과 측정 방법 선정 플로우 차트
<위에서부터 설명>
[실험] 랜덤 비교실험 가능: A/B 테스트
[준실험] 동질로 볼 수 있는 사용자 간 비교 가능: DID/Causal Impact
[관찰] 동질로 간주되는 사용자 간 비교 불가능
영향을 받지 않는 층과의 비교 가능 (영향군과 비영향군이 있음) : 교락 조정
영향을 받지 않은 층과의 비교가 불가(전원이 영향을 받고 있음): 트렌드 비교
DID(디퍼런스 인 디퍼런스)와 Causal Impact(인과 영향)에 대해 간단히 설명해 드릴게요.
### DID(디퍼런스 인 디퍼런스)
DID는 어떤 사건이나 정책이 어떤 영향을 미쳤는지 알아보는 방법입니다.
예를 들어, 학교에서 새로운 수업 방법을 도입했다고 칩시다.이 새로운 수업 방법이 성적에 얼마나 영향을 미쳤는지 알고 싶을 때 사용합니다.
1. 비교 그룹을 만들다 새로운 수업방법을 사용한 클래스(실험그룹)와 사용하지 않은 클래스(대조그룹)를 비교합니다.
2. 전후의 성적을 재다 : 새로운 수업방법을 도입하기 전과 후의 성적을 각각의 그룹에서 측정합니다.
3. 차의 차를 계산하다 : 새로운 수업방법을 도입하기 전후의 성적 변화를 계산하고 그 차이를 비교합니다.
이제 새로운 수업 방법이 성적에 미치는 영향을 알 수 있습니다.
다음 장에서 상기의 각 평가방법의 예를 차례로 소개하겠습니다. (A/B 테스트에 관해서는 아래 링크와 같이 과거 블로그에서도 여러번 소개했으므로 이번에는 할애하겠습니다)
https://note.com/mercari_data/m/mf16f8a98b30a
[シリーズ]A/Bテスト改善|Mercari Analytics Blog|note
メルカリAnalyticsチームがA/Bテストの量・質を改善していくために取り組んでいることをお伝えします。
note.com
2. 어떻게 대처하여 의사결정에 공헌하고 있는가
이 장에서는, 상기 플로우 차트 속의 DID/Causal Impact·교락 조정·트렌드 비교라고 하는 3개의 수법의 상세를 아래의 프레임으로 설명해 갑니다.
Situation: 예를 들면 어떤 상황 하에 있을 때 사용하는가
Typical approach: 어프로치의 개요
Barrier: 그 접근법을 취할 때의 장벽이나 어려운 점
Solution : 위의 Barrier를 해결하기 위한 방법
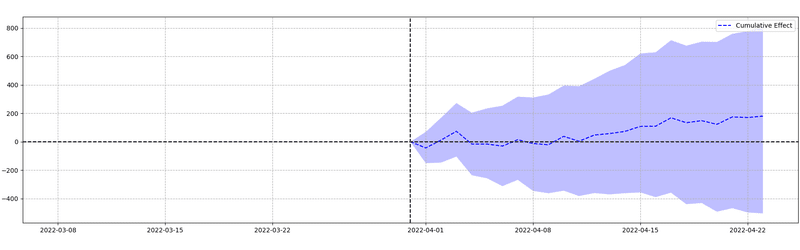
1. DID/CausalImpact
Situation
TV CM에 의한 KPI Lift를 산출하고 싶다.
사용자를 랜덤으로 분할할 수 없으므로 순수한 A/B 테스트에 의한 평가를 할 수 없다.
Typical approach
일부 지역에서만 TVCM을 방영하는 지역 A/B 테스트를 통한 Causal Impact를 이용한 TVCM 효과 측정
※계절성 및 트렌드를 고려할 수 있는 점과 Lift의 신뢰구간을 낼 수 있다는 점에서 DID가 아닌 Causal Impact를 이용한
Barrier
거의 동질적이라고 볼 수 있는 TV CM 방영 지역/비방영 지역의 선정 방법
측정하고자 하는 KPILift를 최대한 정밀하게 측정할 수 있는 treatment 에리어/control 에리어의 조합을 찾는 것이 필요
Solution
A/A 테스트를 실시하여 treatment 에리어/control 에리어를 선정하다.
작년 같은 시기와 가장 최근의 KPI 실적 데이터를 이용하여 Causal Impact를 통한 A/A 테스트를 실시하여 Lift가 플러스도 마이너스도 되지 않는지 확인한다.
p값이 큰지 뿐만 아니라 RMSE나 relative effect 절댓값이 가능한 한 작은 지역을 선정함으로써 정확한 Lift를 검지할 수 있다
### A/A 테스트란?
A/A 테스트는 실험을 수행하기 전에 시스템이나 방법이 제대로 작동하는지 확인하기 위한 테스트입니다.이것은 A/B 테스트(다른 2개의 그룹에 대해 다른 조건을 시험하는 테스트)를 실시하기 전에 이루어집니다.
### 어떻게 하는 거야?
1. 그룹을 만들다 :먼저, 대상이 되는 사람들이나 데이터를 2개의 그룹으로 나눕니다.이 두 그룹은 정확히 같은 조건(예를 들어 같은 웹 페이지나 같은 수업 방법)에 놓입니다.
2. 데이터를 모으다 : 각각의 그룹으로부터 데이터를 모읍니다.예를 들어 웹 사이트의 클릭 수나 테스트 점수 등입니다.
3. 결과를 비교하다 : 두 그룹의 결과를 비교합니다.이상적으로는 두 그룹의 결과는 거의 같아질 것입니다.
### 뭐 때문에 하는 거야?
A/A 테스트는 다음 사항을 확인하기 위해 진행됩니다:
1. 시스템의 확인 : 데이터 수집 및 분석 시스템이 제대로 작동하는지 확인합니다.
2. 임의화 확인 : 그룹 분류가 제대로 랜덤하게 이루어지는지 확인합니다.이것에 의해, 나중에 실시할 A/B 테스트의 신뢰성이 높아집니다.
3. 기준 설정 : 아무것도 바꾸지 않았을 경우의 결과를 아는 것으로, 나중에 무언가를 바꿨을 때의 영향을 정확하게 측정하기 위한 기준을 만듭니다.
### 구체적인 예
예를 들어, 새로운 과자의 맛을 시험하기 전에 A/A 테스트를 실시한다고 합니다.
1. 그룹을 만들다 : 100명의 아이를 2개의 그룹으로 나눕니다(그룹 A와 그룹 B).
2. 같은 과자를 맛보다 : 두 그룹 모두 같은 맛의 과자를 먹도록 합니다.
3. 데이터를 모으다 : 각각의 그룹이 그 과자를 얼마나 좋아하는지를 앙케이트로 모읍니다.
4. 결과를 비교하다 : 두 그룹의 설문 결과가 거의 동일하다면 시스템이나 방법이 제대로 작동하고 있음을 확인할 수 있습니다.
이렇게 해서 A/A 테스트를 함으로써 나중에 수행할 A/B 테스트의 신뢰성을 높일 수 있습니다.
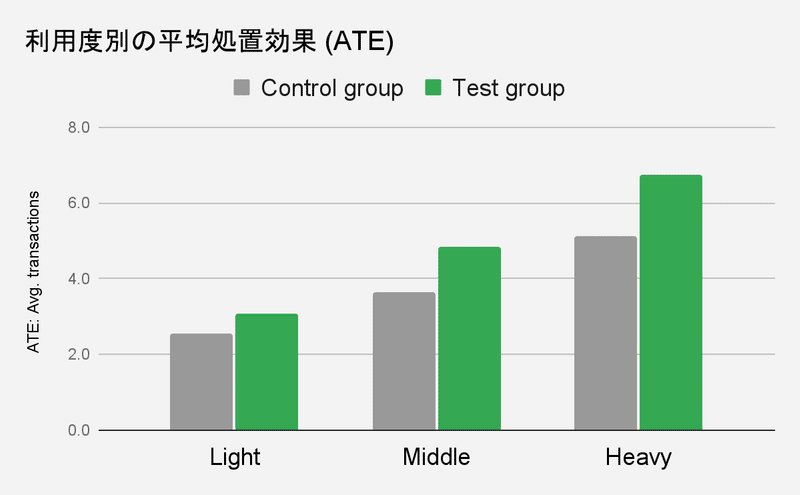
2. 교락 조정 (경향 스코어 매칭/IPW)
Situation
고객이 새로운 기능을 사용함에 따른 사업 영향을 평가하고 싶지만, 그 기능을 이용할지 여부는 고객의 의향에 의존하여 이용자와 비이용자가 단순한 비교를 할 수 없다(교락이 있다)
Typical approach
관찰 데이터에 기반한 경향 점수 매칭 또는 IPW(Inverse Probability Weighting)를 통한 인과 추론
Barrier
어디까지나 정답을 알 수 없는 상황하에서의 통계적인 보정이며, 교란을 어느 정도 보정하고 있고 출력한 결과는 어느 정도 확실성이 있는지 관계자간에 합의하여 의사결정을 하는 것이 어렵다
Solution
결과의 확실성을 통계량뿐만 아니라 재현성으로 나타내고, 관계자가 일정한 확실성을 확인할 수 있는 상태로 만듦으로써 의사결정의 정밀도를 높인다
통계량에 따른 확인의 예
-매칭 후 표준화 평균 차이가 기준치 이하
-모델링시AUC가기준치이상
재현성에 의한 확인의 예
-기능의 이용도를 Heavy/Middle/Light와 같이 양층으로 구분을 만들었을 경우에 결과변수도 순서대로 재현되는지 (순서있는 다중처치)
-시계열로 안정적으로 재현성이 있는지
-유사한 시책으로 유사한 결과가 재현되는가
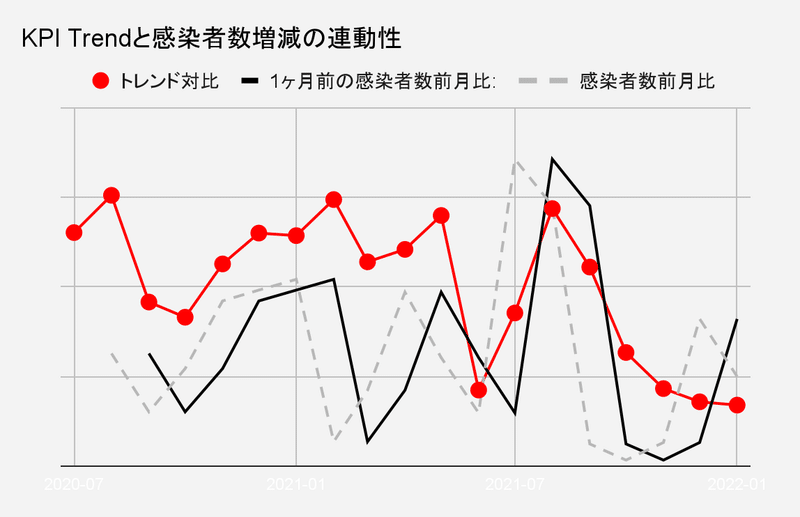
3. 트렌드 비교
Situation
코로나 바이러스의 유행에 따라 라이프 스타일이 변화했다.그로 인한 메루카리에의 사업 영향을 평가하고 싶다
Typical approach
유행 전중후 KPI의 시계열 변화를 관측하여 영향 평가하다
Barrier
시계열의 변화만으로 전체 평가를 실시하면, 그 변화가 코로나 바이러스의 유행에 의한 영향인지, 그 이외의 사건에 의한 영향인지를 구분하는 것이 어렵다
Solution
대상이 되는 사건이 어떻게 사업에 영향을 주는지를 모델화<예, 코로나바이러스 유행도 변화→외출 자제/증가→재택 여가시간 증가/감소→온라인쇼핑 이용기회 증가/감소)
프로세스별 지표화와 어느 지표 간에 어떤 타이밍에 상관관계가 일어나고 있는지 파악
-감염자수→인류→접속수·거래수 트렌드를 각각 파악
-일련의 흐름을 시차를 고려하여 비교함으로써 각 지표의 상관관계를 보다 명확히 할 수 있지 않을까
-결과적으로 감염자 수가 전월 대비 증감→그 1개월 후에 메루카리의 특정 KPI 트렌드가 연동되어 증감하고 있는 것 같다
-실제로 상관계수를 조사하여 이러한 변동에 상관성이 있음을 확인
3. 정리
이번, A/B 테스트(랜덤화 비교 실험)가 어려운 효과 검증에 포커스를 한 지침서의 내용의 일부를 소개했습니다.
서두에도 기재했지만, 이것을 보면 다양한 효과 검증 방법을 누구나 이해할 수 있다는 지침서를 목표로 하고 있습니다.Analytics 팀이 분석면으로부터 한층 더 메루카리의 사업에 스피디하게 공헌할 수도록 향후도 새로운 지견을 얻을 수 있었을 경우는 그때마다 추가해 나가, 브러시 업을 도모해 가고 싶다고 생각하고 있습니다.
[데이터 애널리스트 공부] 데이터를 잘 활용하는 일본기업_메루카리_더 나은 의사결정을 지원하기 위한 효과 검증 지침서!
'데이터 애널리스트 업무 이해하기' 카테고리의 다른 글
| [데이터 애널리스트 공부] 데이터를 잘 활용하는 일본기업_메루카리_[시리즈] A/B 테스트 개선 - 메루카리의 과제 전체상 - (0) | 2024.05.28 |
|---|---|
| 5월 다섯째주_2024년 5월 28일 (화) (0) | 2024.05.28 |
| 5월 다섯째주_2024년 5월 27일 (월) (0) | 2024.05.27 |
| 5월 넷째주_2024년 5월 24일 (금) (0) | 2024.05.24 |
| 5월 넷째주_2024년 5월 23일 (목) (0) | 2024.05.23 |